
Getting better Chat GPT answers.
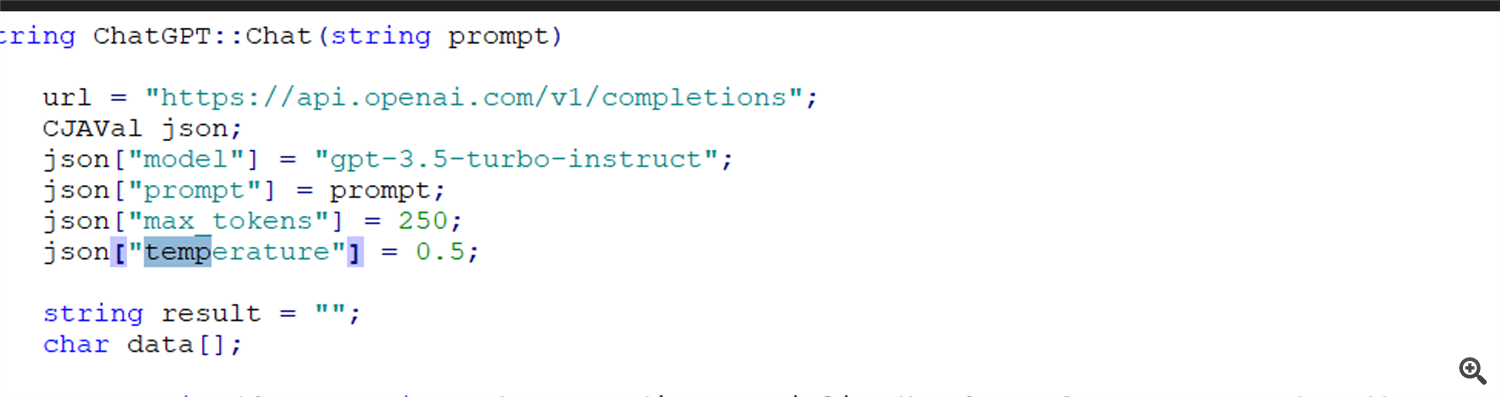
Adjust the temperature and max_tokens parameters for better responses when using OpenAI's models, you can experiment with different values to fine-tune the behavior of the model. Here's how you can use these parameters:
-
Temperature (for Creativity):
-
Higher Temperature (e.g., 0.8 to 1.0): Increasing the temperature makes the output more random and creative. The model becomes more likely to produce diverse responses, including some that may be less coherent or off-topic. This can be useful when you want creative or varied responses.
-
Lower Temperature (e.g., 0.2 to 0.5): Reducing the temperature makes the output more deterministic and focused. The model is more likely to generate responses that are based on the most probable completions, resulting in more coherent and controlled output.
-
Start with a moderate temperature (e.g., 0.5) and adjust it based on the desired level of creativity and randomness in the responses. Lower values make the responses more focused, while higher values make them more creative.
-
-
Max Tokens (for Response Length):
-
The max_tokens parameter allows you to set a limit on the length of the response generated by the model. It can be particularly useful to prevent responses from becoming excessively long or to control the response length for integration into user interfaces.
-
You can set max_tokens to a specific number to limit the response to that number of tokens. For example, if you set max_tokens to 50, the response will be cut off after 50 tokens.
-
Be careful not to set max_tokens too low, as it may truncate responses in a way that makes them incomplete or less meaningful. Experiment with different values to find the right balance.


Comments are closed.